2.2 모델의 정확도 평가
통계학습기법은 왜이렇게 많을까?
→ 통계 분야에서 가능한 모든 자료에 대해 어떤 한 방법이 다른 방법보다 지배적으로 나은 경우는 없다.
→ 그래서! 특정 자료에 대한 적절한 통계학습절차(precedure)를 선택하는 것이 통계에서 가장 어려운 부분이자 핵심이다.
그렇다면 어떻게, 어떤 기준으로 적합한 모델을 선정할 것인가?
1) 적합의 품질 측정: 평균 제곱 오차 (MSE: mean squared error)
- 통계학습의 성능을 평가하려면 예측이 실제값과 얼마나 잘 맞는지(가까운지)를 측정하는 것이 필요하다
- 회귀의 일반적인 측도는 평균제곱오차(MSE: mean squared error)이다.
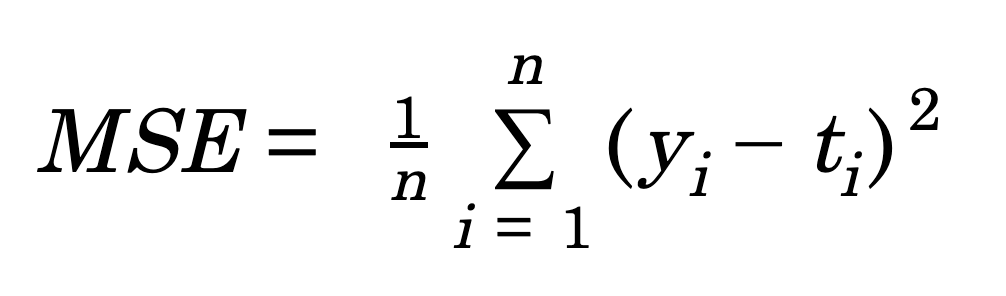
- 위 식은 모델을 적합하는데 사용된 훈련데이터(training data)로 계산되므로, 훈련 MSE라고 할 수 있다.
- 하지만 우리가 실제로 관심 있는 것은 사전에 본적없는 검정 데이터(test data)의 예측정확도이므로 검정MSE가 중요하다.

- 훈련 MSE와 검정 MSE는 처음에는 유연성이 증가함에 따라 줄어든다. 하지만 어떤 지점 이후부터 검정 MSE는 다시 증가하기 시작한다 (오른쪽 그림 붉은색 곡선. U모양을 나타냄)
- 주어진 방법이 훈련 MSE는 작지만 검정 MSE는 큰 결과를 제공할 때, 데이터를 과적합(overfitting)한다고 한다.
- 실제 f가 거의 선형적이라면, 덜 유연한 모델의 검정 MSE가 유연한 모델보다 나을 것이다.
- 실제 f가 몹시 비선형적이라면, 유연한 모델의 검정 MSE가 더 나을 것이다.
- 검정 MSE가 최소가 되는 모델에 대응하는 유연성 수준은 자료에 따라 상당히 다를 수 있다.
- 검정 MSE를 최소로 하기 위해 교차검증(cross-validation)을 사용할 수 있다 -- Chapter 5
2) 편향 - 분산 trade-off
검정 MSE 곡선이 U모양인 이유는, 두 가지 상충되는 성질 때문이다.

- 우리는 검정오차의 기대값을 최소화하는 것을 목표로 하기 때문에 낮은 분산(Variance) 와 낮은 편향(Bias) 를 동시에 달성할 수 있는 통계학습방법을 선택해야한다.
- 분산: 훈련 자료의 변동에 따라 $\hat{f}$이 변동되는 정도.
- 통계학습의 유연성이 높을수록 분산도 높다. 훈련하는 데이터셋에 과도하게 적합하려 하므로, 다른 데이터셋을 훈련시킬 경우 f̂이 많이 변동될 수 있다. (데이터 포인트 중 어느 하나를 변화시키면 추정치 f̂이 크게 변할 수 있음을 의미)
- 편향: 실제 문제를 훨씬 단순한 모델로 근사시킴으로 인해 발생되는 오차
- 통계학습의 유연성이 높을수록 편향은 낮다.
- 분산과 편향의 상대적 변동율이 검정 MSE의 증가-감소를 결정한다.
- 통계 방법의 유연성을 증가시킴에 따라 편향이 분산보다 빠르게 감소한다. 하지만 어떤 지점에서 유연성 증가는 편향에 크게 영향이 없지만 분산은 크게 증가시키기 시작한다.
- 실제 f가 선형에 가까울수록 모델이 유연해짐에 따라 분산의 증가폭이 커지므로 덜 유연한 모델을 선택하는 것이 좋다.
- 실제 f가 비선형적일수록 모델이 유연해짐에 따라 편향의 감소폭이 커지므로 유연한 모델을 선택하는 것이 좋다.
- 아래 그래프 추이를 통해 확인하자.

3) 분류 문제의 모델 정확도
- 분류 문제에서도 아래와 같이 훈련오차율(training error rate)을 계산하여 모델 정확도를 측정할 수 있다.
$\frac{1}{n}$ $\sum_{i = 1}^{n} $ $I$($y_{i}$ ≠ $\hat{y}$$_{i}$)
* $\hat{y}$$_{i}$ : $\hat{f}$를 사용하여 예측된 i번째 관측치의 클래스 (label)
* $I$($y_{i}$ ≠ $\hat{y}$$_{i}$) : 지시변수 (indicator variable). $y_{i}$ ≠ $\hat{y}$$_{i}$ 이면 1, $y_{i}$ = $\hat{y}$$_{i}$ 이면 0을 출력
- 즉, 훈련 오차율은 전체 예측 중 잘못 예측(분류)한 비율을 나타낸다.
- 하지만 분류에서도 마찬가지로 우리가 궁금한 것은 훈련오차율이 아닌 검정오차율(test error rate)이다!
(1) 베이즈 분류기 (Bayes Classifier)
주어진 설명변수 값에 대해 가장 가능성이 높은 클래스에 각 관측치를 할당하는 분류기
Pr(Y = j | X = $x_{n}$)*가 가장 큰 클래스 J에 할당되어야 한다.
* 관측된 설명변수 벡터 $x_{n}$이 주어진 경우, Y=j 인 조건부 확률
- 베이즈 오차율: 1 - E(maxPr(Y = j | X). 오차율의 평균값
- 질적 반응변수에 대한 모델 성능 측정은 이론상 베이즈 분류기를 이용하는 것이 가장 좋지만, 실제 데이터에는 주어진 X에 대한 Y의 조건부 분포를 모르므로 베이즈 분류기 계산이 불가하다.
- 베이즈 분류기는 다른 방법들을 비교하는 '표준'의 역할을 한다.
(2) K-최근접 이웃(K-Nearest Neighbor)
- 최근접 이웃 분류기 할당 방법
① 양의 정수 K와 검정관측치 $x_{0}$에 대해 훈련데이터 $x_{0}$에 가장 가까운 K개의 점을 식별한다.
② 그 다음, 클래스 j에 대한 조건부확률을 반응변수 값이 j인 $N_{0}$ 내 점들의 비율로 추정한다.
③ 마지막으로 베이즈 분류기를 적용하여 검정관측치 $x_{0}$를 확률이 가장 높은 클래스에 할당한다.
- K의 선택은 KNN 분류기에 영향을 미친다.
- K = 1일 때 결정경계는 지나치게 유연하고 베이즈 결정 경계와 맞지 않는 데이터 패턴들을 발견한다. (편향은 낮지만 분산은 높음)
- K = 100일 때 결정경계가 덜 유연해지고 점점 선형에 가까워 진다. (분산은 낮지만 편향은 높음)
- 회귀와 분류에서 올바른 수준의 모델 유연성을 선택하는 것은 통계학습방법 성공에 아주 중요하다.
- 편향-분산 절충과 검정오차(오류)의 U모양은 유연성 수준 선택을 어렵게 만든다.
--> Chapter 5에서 검정오차율을 추정하여 최적의 유연성 수준을 선택하는 방법에 대해 배울 예정이다.
* 이 내용은 An Introduction to Statistical Learning 교재를 개인적으로 요약한 내용입니다.
* 이미 노트로 정리한 내용을 블로그에 옮기다보니, 개별적으로 출처 표시가 없습니다...
Chapter 4부터는 참고해서 작성한 내용이 있다면 링크를 남길 예정입니다.
* 데이터분석을 공부하는 비전공자로, 정리 내용이 조금 미흡하거나 잘못되어 있을 수도 있습니다.(공부중입니다. ㅠㅠ)
* 수정 필요한 내용이 있거나 궁금한 점이 있으면 부드럽게 댓글 부탁드려요^^
* 참고자료: https://wikidocs.net/30728
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
'통계 > ISLR' 카테고리의 다른 글
| Chapter 3. 선형회귀 (Linear Regression) - 그 외 내용 (0) | 2020.04.28 |
|---|---|
| Chapter 3. 선형회귀 (Linear Regression) - 3) 회귀모델에서 다른 고려할 사항 (0) | 2020.04.28 |
| Chapter 3. 선형회귀 (Linear Regression) - 2) 다중선형회귀 (1) | 2020.04.28 |
| Chapter 3. 선형회귀 (Linear Regression) - 1) 단순선형회귀 (0) | 2020.04.27 |
| Chapter 2. 통계학습 - 1) 통계학습이란? (0) | 2020.04.08 |

